
Vi økonomer forsøker ofte å modellere hvordan fremtiden vil bli. Økonomer er i grunn en gruppe synsere som tar et lass med forbehold etter at vi har synset om noe. Målet med den mer eller mindre begrunnede synsingen er at man skal gjøre fremtiden noe mer forutsigbar enn den vil være om man bare tar den helt som den kommer, etter hvert som den kommer.
Onde tunger vil selvsagt hevde at vi ikke er spesielt flinke til det. Du kan vel telle på omtrent en hånd de som klarte å se finanskrisen komme, for eksempel. Og de har rett. Dette er ikke lett. Spørsmålet er bare om det ville vært bedre å ikke forsøke en gang. Jeg tror svaret på det er nei.
Det har vært reist betydelig kritikk rundt bruken av såkalte Value at Risk modeller. Dette er modeller som sier noe om risiko, gitt at verden utvikler seg noenlunde normalt. Og som kjent utvikler den seg noen ganger ikke normalt i det hele tatt. Noen ganger dukker det opp svarte svaner ((Fra Nassim Talebs bok «The black swan: The impact of the highly improbable»)), selv om de omtrent ikke finnes. Og når disse svarte svanene dukker opp, faller forutsetningene for normaliserte modeller sammen.
Men likevel – ville det vært bedre og ikke forsøke å si noe om fremtiden i sin normaliserte form? Det tror jeg ikke. Men det er viktig å ha klart for seg hva modellen kan si noe om og hva den ikke kan si noe om. Samt at dersom man bare planlegger for svarte svaner, så vil man ikke tørre å ta den risiko som er nødvendig for å satse innenfor enhver sektor og enhver bedrift.
Enhver modellering av fremtiden er basert på forutsetninger om hvordan ulike variable vil utvikle seg. Det gjelder enten det er en deterministisk modell (der forutsetninger betraktes som parametre med kjent utfall), eller en usikkerhets-modell (der forutsetningene betrakes som parametre med ukjent utfall).
For å finne gode forutsetninger for fremtidig utvikling må vi både forstå hvordan virksomheten er skrudd sammen i nå-situasjonen og vi må mene noe om hvordan den vil se ut fremover. Det første vi bør gjøre for å si noe om fremtiden, er å studere hvordan fortiden har vært.
Siden jeg har et kvantitativt fokus, vil det første jeg gjør være å se om jeg har historiske data som viser hvordan sammenhengene har vært i fortiden. Det er en rekke statistiske og finansielle metoder/verktøy som kan brukes. Målet er å forsøke å finne de viktigste faktorene som driver virksomhetens lønnsomhet, og fokusere på disse når man skal si noe om fremtiden. Som regel fungerer 80/20 regelen veldig bra.
Og som jeg ser det er det ALLTID en fordel å ha historiske data. Ikke fordi historien alltid gjentar seg, men fordi historien har noen verifiserbare faktiske forhold ved seg som gir et bilde av hvordan verden har vært. Å vite det er alltid bra. Men når man gjør analyser på hsitoriske data, og finner sammenhenger så er det noen viktige spørsmål man bør stille seg, eller en prosess man bør gjennom for å si det på en annen måte. Den kan illustreres med følgende enkle skjematiske fremstilling:
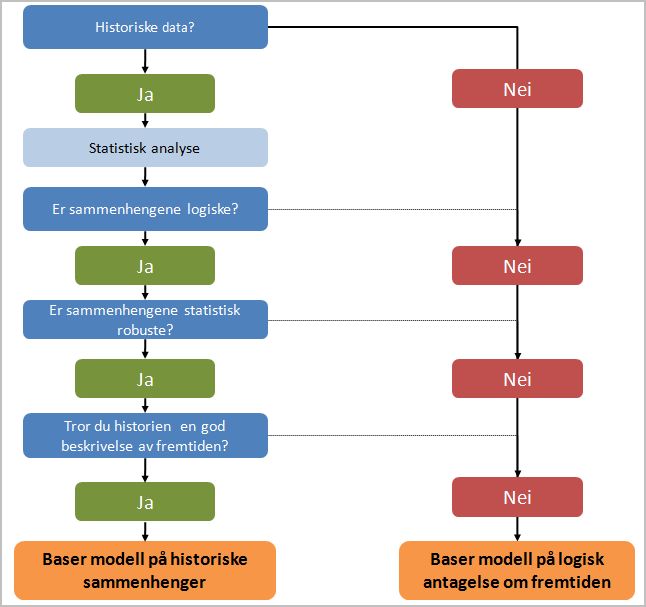
Dataanalysen er en prosess der man underveis stiller seg spørsmål som vil gi svar på hvorvidt det er mulig å bruke historiske data til å si noe om fremtiden.
Er resultatene/sammenhengene logiske?
Hvis nei, er det flere ting man kan gjøre, for eksempel utvide analysen og undersøke om det er en årsak bak sammenhengen som enda ikke er inkludert i analysen.
Norske strømpriser samvarierer med ølprisene i Australia. Det kan godt være en samvariasjon (vinter i Norge, høy strømpris, sommer i Australia, høy ølpris), men den ene forårsaker ikke den andre. Det er tilfeldig. Det er ingen logikk i at norske strømpriser kan spås ved å se på ølprisene i Australia.
Noen ganger sitter man rett og slett der med en sammenheng som ikke virker logisk. Da taler mye for at den er tilfeldig, og dermed ubrukelig til å si noe om fremtiden.
Er sammenhengene robuste?
Det er fullt mulig å finne statistiske sammenhenger mellom de fleste datasett, men det betyr ikke at resultatene er statistisk holdbare. Er de ikke det, må du gå tilbake og analysere data videre, eventuelt konkludere med at du ikke har data som har en sammenheng som er statistisk signifikant.
Vil historien være en god modell for fremtiden?
Selv om du har signifikante, logiske sammenhenger i fortiden trenger det ikke å bety at de er der i fremtiden. For verden endres. For eksempel: mens jeg og flere med meg leste 3 papiraviser om dagen, leser vi nå nyheter på nett. Dermed må du hele tiden diskutere hvorvidt du skal frigjøre deg fra det du vet om historien og heller bygge opp en modell som avspeiler det du tror. Spesielt interessant blir det selvsagt siden folk tror og mener ulike ting.
Der historien er et faktum (NB å forstå den er ikke like enkelt) så er fremtiden preget av usikkerhet. Vi vet ikke hva som vil skje. Vi gjør antagelser. Og det er fristende å bruke historien til å predikere fremtiden dersom vi har et datagrunnlag som er robust nok. Faktisk er det tungt å argumentere for noe annet. Men vi vet jo at historien ikke alltid er den beste beskrivelsen av fremtiden.
Det jeg i hvert fall er sikker på, er at det er bedre å forsøke å estimere fremtiden enn å ikke gjøre det. Vi bør bare være klare over hvilke begrensninger som helt klart ligger innebygget i modellene våre. Og ikke tolke en 99% Value at Risk (absolutt nedside i 99% av tilfellene) som (helt) sikker. For ikke vet vi når 1% inntreffer, og ikke vet vi hvor stor effekten er.
Men det er uansett best å ha en analyse i bunn.
